Getting Started With Trees
Tuesday - 8th Dec ~ by Abhishek

A Tree is an important element, not just in the real world but also when it comes to
Programming, Data Science, etc. In Computer Science, a Tree is an important Data Structure which
is useful for storing hierarchically ordered data.
If you have read about data-structures, you are probably aware and well acquainted with linear
data structures like Arrays, Linked-list, Stacks, Queues, etc. Trees are non-linear data
structures which most of us think as something very complex and end our journey into data
structure at Trees itself .
In simplest of terms, a Tree is a data structure consisting of collection of nodes connected by
edges (which don’t form a closed loop). They are a hierarchical non-linear structure because
they don’t store the data in a linear fashion as in case of arrays or lists.
Each Tree will have root node and the nodes related to it will be connected to the root node as
its children. Let’s look into some important terms used in Trees and what these terminology
exactly mean :
1. Root → The topmost node in the hierarchy of the tree data-structure is
known as the Root node.
2. Child → A node which has a parent is called as the Child node of the parent.
3. Root → A node that is just previous to the current node is called as the Parent node of current node.
4. Edge → A link between any two nodes is called as edge or link of those two nodes.
5. Leaf → A node that doesn’t have any child nodes is called as Leaf node of the Tree.
6. Height → The height of a node is number of edges from given node to the Root node.
7. Depth → The depth of a node is length of the path from Root of the Tree to the given node.
There are few other lesser used terminologies like Ancestors, Descendants, Tree degree, etc which are pretty self-explanatory and not commonly used. Now that we have understood the basic terminologies of a tree, let’s look into the different kinds of Trees that we can have.
This article gave you a brief overview of Tree data structures, their working and their usage and applications. It might be overwhelming to understand all the different kinds of Trees at first, but the basics are the same in every case🙂. I hope this article will help you in understanding the basics and getting started with using Trees !
Getting Started With Graphs
Wednesday - 9th Dec ~ by Abhishek

Graphs are one of the most important and frequently used data-structures in Computer Science. They are used in many applications that we use daily like Facebook, Google Maps, Airline Networks, Recommendations Engine and many other use cases which are essential in our daily lives.
Graphs, in the simplest of terms, are just some collection of nodes connected by some edges. We usually denote graphs as set of vertex and edges by the notation — G = (V,E).
If you know about trees, you can consider Graphs to be Trees with fewer restrictions. A graph is a superset of Trees where there are no rules like non-existence of cycle.
Lets dive in more into Graphs by looking at their types.
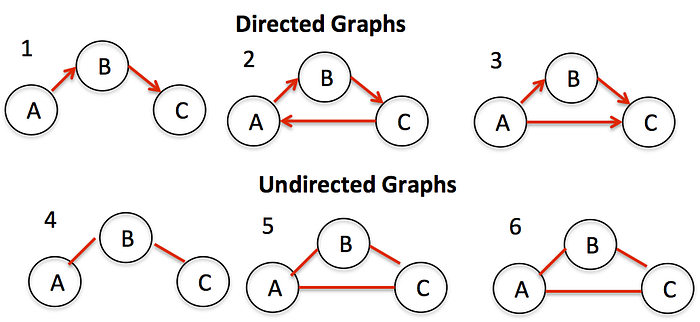
1. Directed And Undirected Graphs → Directed Graphs refer to graphs in which there is an edge from node A to node B (in Graphs,Vertex are also called as Nodes). Undirected Graphs are those in which there is an edge from Node A to Node B and the same edge also implicitly specifies that the edge connects Node B to Node A
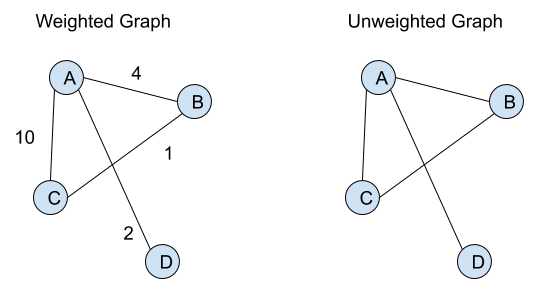
2. Weighted And Unweighted Graphs → A Graph in which edges are given weights are known as Weighted Graphs. A graph where edges are specified without assigning weights to them are called Non-Weighted or Unweighted Graphs.
3. Sparse And Dense Graphs → When the number of edges in a graph is more, we call it as Dense Graphs and when the number of edges are less, they are known as Sparse Graphs. There are at max V² number of edges possible in a Graph. So, we generally call a graph having edges close to V² as Dense Graph and vice-versa.

We probably have encountered graphs in Mathematics in our school or colleges. Graphs in Computer Science are similar to it with few differences when it comes to how we represent a Graph. Lets see how we represent Graphs in computers and the different types.
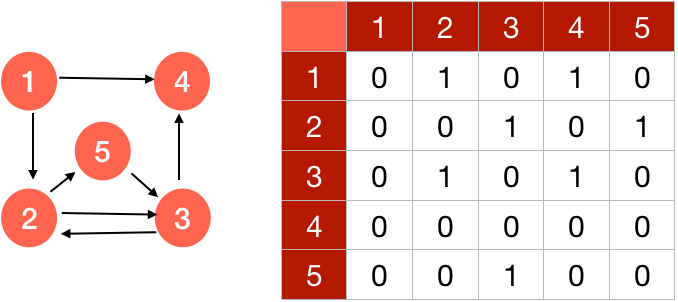
1. Adjacency-Matrix Representation → In this form of representation, we use a V x V matrix to represent the graph. Each cell of the matrix will either specify if an edge exists between two vertex (in case of Non-weighted Graphs) using 1-edge present or 0-edge absent, or specify the weight of edge between two vertex(in case of Weighted Graphs).
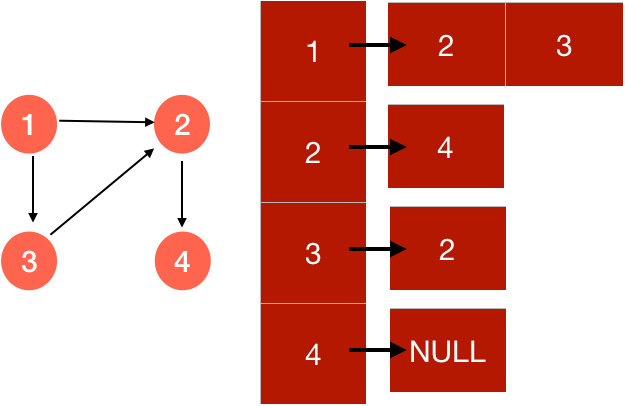
2. Adjacency-List Representation → In this form of representation, for each node we use a list to represent all the nodes connected to it. So, we are maintaining an array of V lists, where each of the list will specify all the nodes connected to the corresponding numbered node.
At first, Graphs and these algorithms may feel intimidating, but implementing these algorithms is easy once we understand the way they work. Graph is one of the topics in Computer Science where many people face difficulty in grasping the ideas and concepts behind it. But once you get started with it and have enough hands-on practice with them, you will surely start getting the core concepts behind them and implementing them would be easy.
Graphs are a powerful data-structure used in various aspects of our Life and Technology. There’s still a lot to learn in Graphs and Graph theory. Hopefully, this article would have cleared the basic concepts related to Graphs and help you get started with them 🙂.